This post discusses one of my favorite academic projects. This work was largely done while I was a visiting researcher at the wonderful Imperial College of London.
I remember literally staring at the math behind my lab’s latest research work. I was a student at UCLA, and our lab just was on a high from having made the cover story on Scientific American. The lab worked on the (then hot hot hot) topic of reconfigurable computing. Specifically, we worked on machines that would perform image correlation very quickly; my specific project performed at 12FPS running at just a 16MHz clock!
What struck me was that what the machine was doing could represent a more generic way of how machines performed mathematics — vector math, to be precise. So over the course of about a summer, I wrote the following paper (I also wrote the actual C++ code that did the work, but can’t track it down!). Here’s what that code could do:
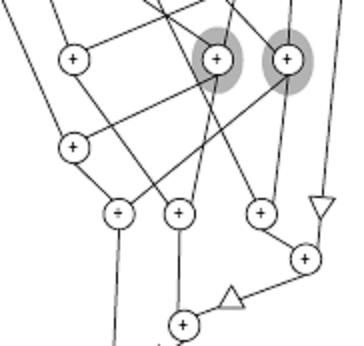
Re-write the following equation, using simple arithmetic, so that all multiplies are done using powers of two, and with the fewest number of adds or subtracts:
There are 7 plus signs already — how many more will you need so that there are only powers of two? (Answer at the end of this post!)
This is exactly the sort of optimization that is needed to minimize hardware design complexity (a multiply by a power of two is just a shift, after all). I loved this project because it transformed this algebraic problem into a graph coloring problem, and by doing so, allows computers to do all the dirty work. For example, if you gave the code a fixed point representation of the DCT, it would optimize and transform the 8×8 matrix multiply to something that approximates the widely used version by Feig & Winograd. Except it took the computer just about a day to do it.
Abstract
This paper presents a method, called multiple constant multiplier trees (MCMTs), for producing optimized reconfigurable hardware implementations of vector products. An algorithm for generating MCMTs has been developed and implemented, which is based on a novel representation of common subexpressions in constant data patterns. Our optimization framework covers a wider solution space than previous approaches; it also supports exploitation of full and partial run-time reconfiguration as well as technology-specific constraints, such as fanout limits and routing. We demonstrate that while distributed arithmetic techniques require storage size exponential in the number of coefficients, the resource utilization of MCMTs usually grows linearly with problem size. MCMTs have been implemented in Xilinx 4000 and Virtex FPGAs, and their size and speed efficiency are confirmed in comparisons with Xilinx LogiCore and ASIC implementations of FIR filter designs. Preliminary results show that the size of MCMT circuits is less than half of that of comparable distributed arithmetic cores.
Download the full paper (PDF), or browse through the paper below (it looks blurry cuz the font wasn’t properly embedded, crap.)